Building Transformer-Based Entity Linking System
History and step by step guide.
[Updated at 18th April, 2021] You can run experiments at your own Colab-Pro environment. For further details, see here.
History
Entity Linking (EL) is the task of mapping a range of text in a document, called a Mention, to an entity in a knowledge graph, and is considered one of the most important tasks in natural language understanding and applications.
For example, when a user says, “I saw Independence Day today, and it was very exciting,” in a chatbot dialogue, no one would think this as anniversary.
This is just one example, but entity linking is a very important task for subsequent problems related to NLP.
In this article, we will create two simple entity linking systems based on Bi-encoder. The former is based on surface-based candidate generation (CG), and the latter on Approximate Nearest Neighbor Search (ANNSearch).
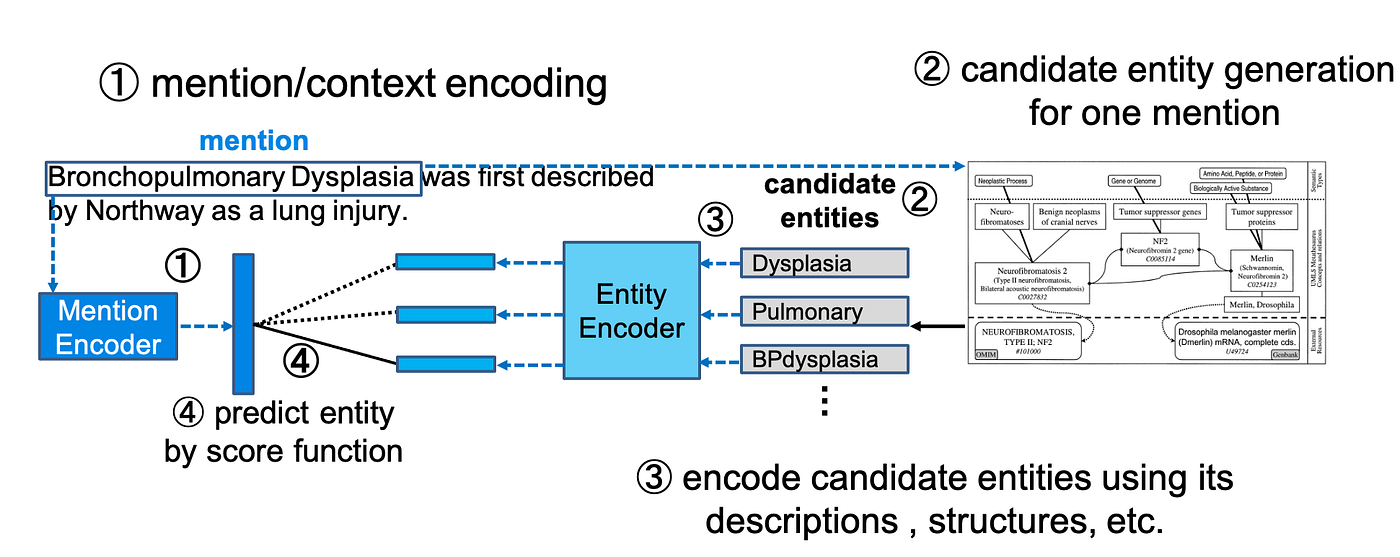
Until 2019, entity linking models were trained by feeding a neural net with string similarity between mentions and entities, co-occurrence statistics in Wikipedia (features called priors in the early papers), context in which mention exist, and so on.
As it requires high computational costs to compare all entities in a knowledge base with each mention, previous work used such statistics, or alias tables for candidate generation; i.e., to filter entities to consider for each mention. (Yamada et al., 2016; Ganea and Hofmann, 2017; Le and Titov, 2018; Cao et al., 2018).
For an alias table to be effective, it must incorporate a large number of mentions occurring in target documents. This is not an issue for entity linking from generic documents, owing to Wikipedia and its rich annotation of anchor texts available to create an alias table. By contrast, building an effective alias table is difficult and costly in specialized domains, as Wikipedia’s coverage is often inadequate for these domains, and a large domain-specific corpus of anchor texts can be hardly found.

When an alias table is not available or has limited coverage, candidates can be generated by the surface similarity between mentions and entities (Murty et al., 2018; Zhu et al., 2019). However, capturing all possible entities for a mention by its surface similarity is extremely difficult if not impossible, especially in biomedical literature wherein entities often exhibit diverse surface forms (Tsuruoka et al., 2008). For example, the gold entity for the mention rs2306235, which occurs in the St21pv dataset (Mohan and Li, 2019), is PLEKHO1 gene. However, this entity is likely to be overlooked in surface-based candidate generation, as it does not share a single character with rs2306235.
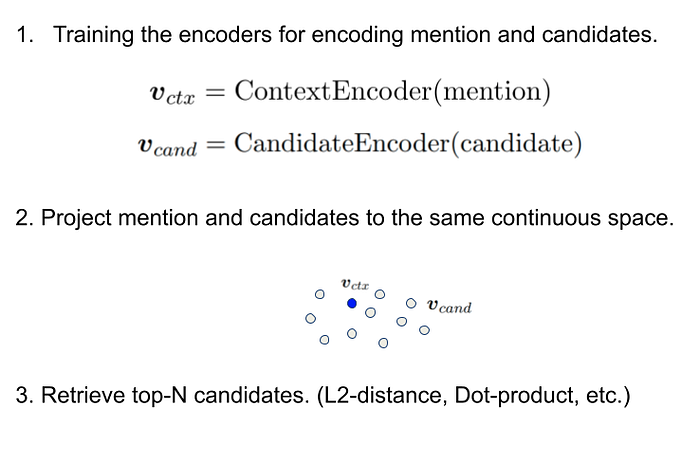
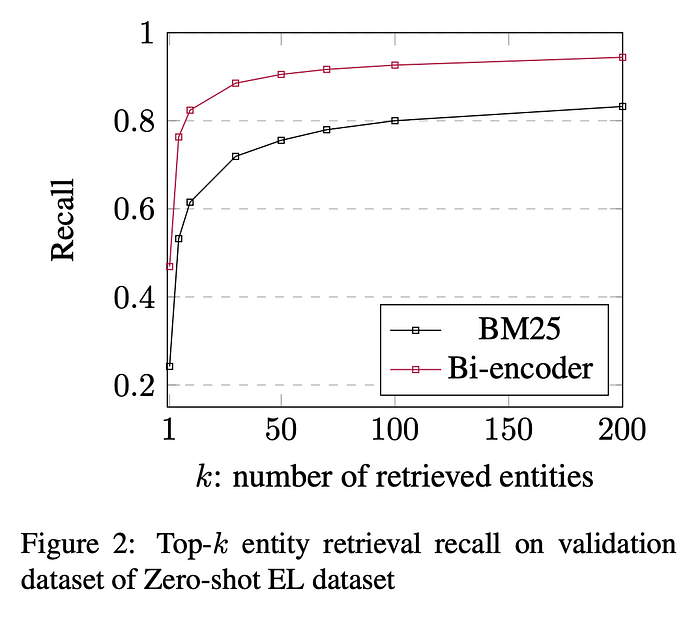
To mitigate the dependence on alias tables, Gillick et al. (2019) proposed using the approximate nearest-neighbor (ANN) search. Although their method successfully abstained from using alias tables, it instead requires a large corpus of contextualized mention-entity pairs for training, which is rare in specialized domains. Wu et al. (2019) proved that Bi-encoder is still useful for entity candidate generation in similar setting, such as Zero-shot one which Logeswaran et al. (2019) proposed, but the accuracy is still far below that of the general domain, and further research is expected in this setting.
In this article, we will implement entity linking using Bi-encoder. We will implement two types of candidate generation, one based on surface forms and the other using approximate neighborhood search.
Source Codes
Source codes are here.
https://github.com/izuna385/Entity-Linking-Tutorial
Data Preprocessing
Written in the above source codes. In this article, we use BC5CDR (Li et al. (2016)) dataset for training and evaluating model.
BC5CDR is a dataset created for the BioCreative V Chemical and Disease Mention Recognition task. It comprises 1,500 articles, containing 15,935 chemical and 12,852 disease mentions. The reference knowledge base is MeSH, and almost all mentions have a gold entity in the reference knowledge base.
In this article, we preprocessed Pubtator format documents by using scispacy in parallel processing. Here is the tool used for this preprocessing.
https://github.com/izuna385/PubTator-Multiprocess-Parser
https://github.com/izuna385/ScispaCy-Candidate-Generator
Model and Scoring
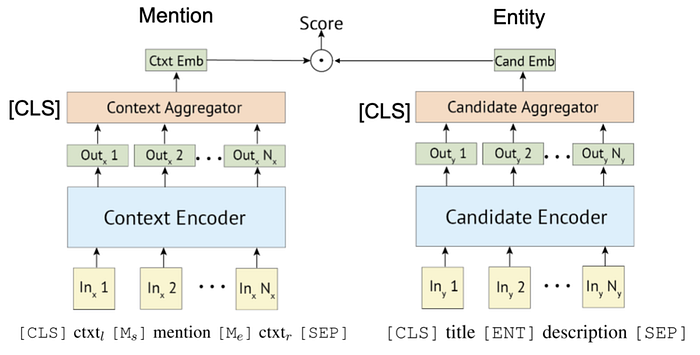
The encoder for the model and candidate entities is a very simple structure. We will use embeddings that are encoded from the link target range and surrounding word pieces. We will also use an embedding that is generated from the entity name and description.
Candidate Generation
For surface-based CG, we use ScispaCy for two reasons. The first is that the dataset we are working on, BC5CDR, belongs to the biomedical field, and the second is that ScispaCy itself has a superficial form-based candidate generation function. For ANN-based CG, we will use faiss.
Training
To save negative examples when training with BERT, we use in-batch negative sampling here.
In this learning method, it is possible to train the encoder more rigorously by increasing the batch size, but this also increases the GPU resources required. In this experiment, we have confirmed that training is possible even with a batch size of 16 🙂.
Evaluation and Results
We use two methods for candidate generation: surface form and approximate neighborhood search, but the final prediction uses the inner product of the mention and entity embeddings for both.
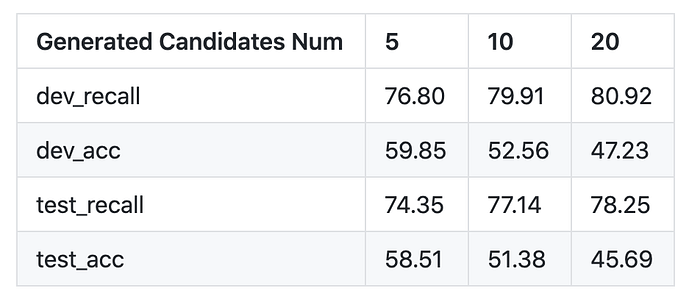
- Surface-based CG
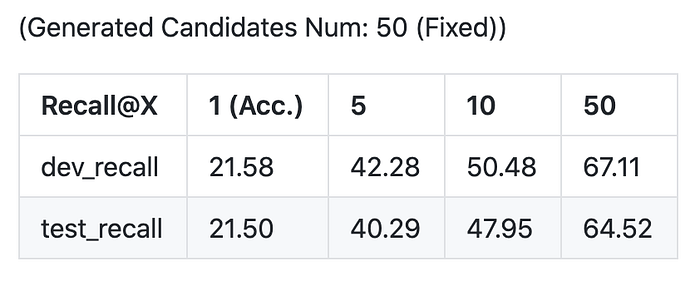
- ANN-based CG
Discussions and Further Directions
The final correct answer rate was about 50% for the surface form-based candidate generation. In this case, we used inner product for the final prediction, but in fact, surface similarity is another important feature in prediction. In addition to scoring between embeddings, it is conceivable to prepare a scoring function that takes character similarity into account.
In addition, the data set used in this study is only about 10,000, which is only 1/10000th of the number of data used in Gillick et al. From this, we can infer that our model successfully encodes the context and entity information into the embedding.
GitHub Repository
- https://github.com/izuna385/Entity-Linking-Tutorial
- Also, if you are further interested in Entity Linking, you may also like
https://github.com/izuna385/Entity-Linking-Recent-Trends
Feel free to contact or create an issue!
References
- Joint Learning of the Embedding of Words and Entities for Named Entity Disambiguation
- Deep Joint Entity Disambiguation with Local Neural Attention
- Improving Entity Linking by Modeling Latent Relations between Mentions
- Neural Collective Entity Linking
- Hierarchical Losses and New Resources for Fine-grained Entity Typing and Linking
- LATTE: Latent Type Modeling for Biomedical Entity Linking
- Normalizing biomedical terms by minimizing ambiguity and variability
- Learning Dense Representations for Entity Retrieval
- Zero-Shot Entity Linking by Reading Entity Descriptions
- Scalable Zero-shot Entity Linking with Dense Entity Retrieval
- BioCreative V CDR task corpus: a resource for chemical disease relation extraction
- Poly-encoders: Transformer Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring